
Regular Expressions
Match的东西开头写上r会好理解很多
/1 /2的含义
用r'([a-z]+)_([0-9])'来匹配’aaaaa python_33 adfafafd',会匹配到python_33 其中,\0表示整个字符串,即“python_33”; \1表示第一个小括号对应内容,即“python”; \2表示第二个小括号对应内容,即“33”。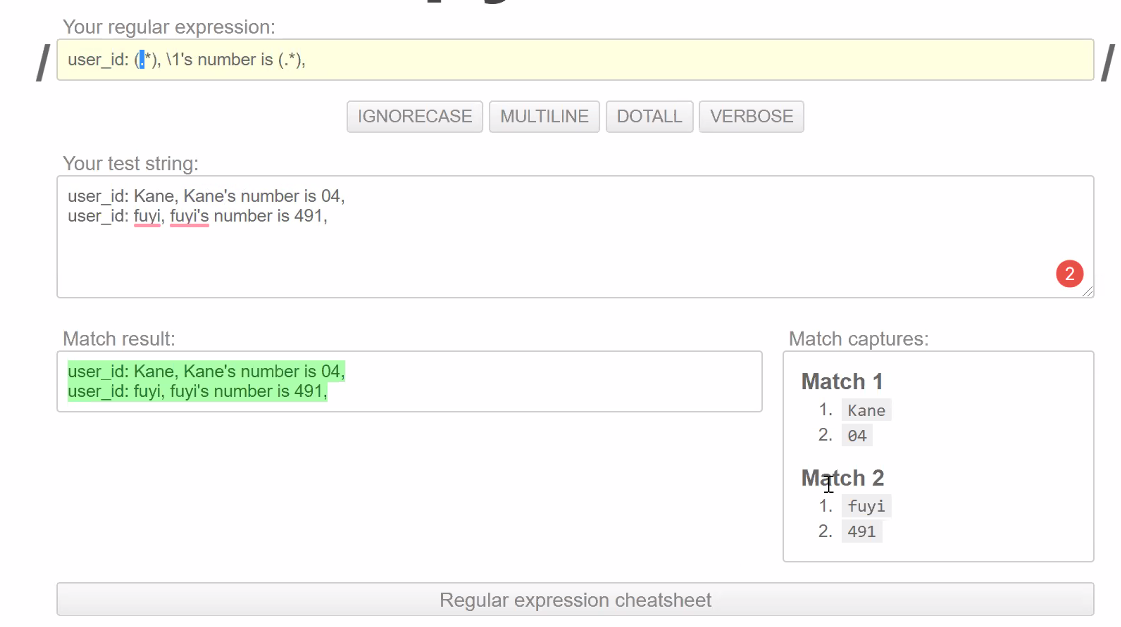
三种匹配的区别
1. return 所有符合的 2. return 开头是l的 3. return first match
获取匹配和非获取匹配
总结一下,()里面的东西,在后面可以通过/1提取出来,但有些时候不需要把括号里面的东西捕获,至少想用括 号分下组,因此就用(?:)在开头用于单纯的分下组。
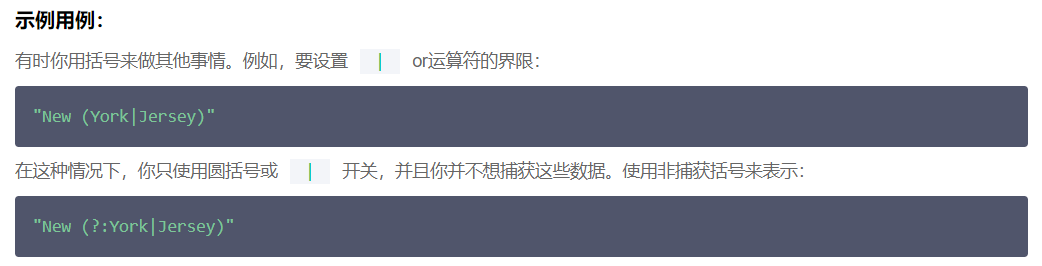
例子
澳洲车牌XRA 000 [A-Z0-9][A-Z][A-Z]\s[0-9][A-Z0-9][A-Z0-9] 非运算符[^b] [^b]og -- 不匹配bog 常用缩写*+?的用法
分组 (abc)+ "Incident American Airlines Flight 11 involving a Boeing 767-223ER in 2001" Incident (.*) involving Greedy strategy 尽可能多的匹配 .*\d+ number 516 结果:number 51 Lazy strategy 尽可能少的匹配 *? .*?\d+ number 516 +? ?? 结果:number If it is in a greedy way, dot can match any character, including" If it is in a lazy way, dot will not match" OR A|B \
If my re is "hello$", it means I want to check if the word "hello" is at the end of a string. :? means non-capturing group. We don’t capture the result of a group. We use group to make the regular expression looks more clear to us. IP地址的匹配 str1 = re.findall(r'([0-9]{1,3}\.){3}[0-9]{1,3}',text)